https://leetcode.com/problems/number-of-ways-to-form-a-target-string-given-a-dictionary/
首先,在組合出 target 的過程,取哪一個 word 其實不重要,重要的是取了第幾個 character。我們可以把 words 裡面的資訊變成 freq[i][j],freq[i][j]爲「words 中,第 i 個 (0 indexed) character 出現 j 這個英文字母的次數」。
例如: words = ["acca","bbbb","caca"],那麼 freq[3][0] 就是「words 中,第 3 個 character 出現 ‘a’ 這個英文字母的次數」,也就是 2。
接下來定義 dp[i][j] 爲 「每一個 word 的前 i 位 (1 indexed) 配出 target 的前 j 位 (1 indexed) 的方法數」。下面文字的部分沒有特別講都是 1 indexed。
對於 dp[i][j],
如果決定在第 i 位選出 target 的第 j 位,那麼方法數就是 dp[i - 1][j - 1] * freq[i - 1][target[j] - 'a'](freq 是 0 indexed)。
如果決定不在第 i 位選出 target 的第 j 位,那麼方法數就是 dp[i - 1][j] 。
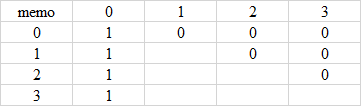
例如: words = ["acca","bbbb","caca"], target = "aba",dp[3][2] 等於在問 words = ["acc","bbb","cac"], target = "ab" 的方法數。
如果決定在第 3 位選出 target 的第 2 位(也就是 ‘b’),那麼有 dp[2][1] * 1(因爲只有 "bbb" 的第 3 位是 'b') 種方法數。
如果不選的話,那麼有 dp[2][2] 種方法數。
當 j == 0,一共有 1 種方法數,也就是什麼都不選。
當 i < j,一共有 0 種方法數,因爲不可能選到。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| int numWays(vector<string>& words, string target) {
int n = words[0].size();
int m = target.size();
int mod = 1e9 + 7;
vector<vector<int>> freq(n, vector<int> (26, 0));
for (string word: words){
for (int i = 0; i < n; i++){
freq[i][word[i] - 'a']++;
}
}
// memo[i][j] = first i characters in word, ways to form target[j:]
vector<vector<long long>> memo(n + 1, vector<long long> (m + 1, 0));
function<long long(int, int)> dp = [&](int i, int j) -> long long {
if (j == 0){
return 1;
}
if (i < j){
return 0;
}
if (memo[i][j] > 0){
return memo[i][j];
}
memo[i][j] = (dp(i - 1, j) + dp(i - 1, j - 1) * freq[i - 1][target[j - 1] - 'a']) % mod;
return memo[i][j];
};
return dp(n, m);
}
|
time complexity: O( nk + nm )
space complextiy: O( 26n + nm )
where n = words[0].size(), m = target.size(), k = words.size()
也可以改成 bottom up 的寫法:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
| int numWays(vector<string>& words, string target) {
int n = words[0].size();
int m = target.size();
int mod = 1e9 + 7;
vector<vector<int>> freq(n, vector<int> (26, 0));
for (string word: words){
for (int i = 0; i < n; i++){
freq[i][word[i] - 'a']++;
}
}
vector<vector<long long>> memo(n + 1, vector<long long> (m + 1, 0));
for (int i = 0; i <= n; i++){
for (int j = 0; j <= i && j <= m; j++){
if (j == 0){
memo[i][j] = 1;
}
else {
memo[i][j] = (memo[i - 1][j] + memo[i - 1][j - 1] * freq[i - 1][target[j - 1] - 'a']) % mod;
}
}
}
return memo[n][m];
}
|
計算 memo[i] 時只有用到 memo[i - 1],可以進一步優化空間複雜度。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
| int numWays(vector<string>& words, string target) {
int n = words[0].size();
int m = target.size();
int mod = 1e9 + 7;
vector<vector<int>> freq(n, vector<int> (26, 0));
for (string word: words){
for (int i = 0; i < n; i++){
freq[i][word[i] - 'a']++;
}
}
vector<long long> memo(m + 1, 0), prev(m + 1, 0);
for (int i = 0; i <= n; i++){
for (int j = 0; j <= i && j <= m; j++){
if (j == 0){
memo[j] = 1;
}
else {
memo[j] = (prev[j] + prev[j - 1] * freq[i - 1][target[j - 1] - 'a']) % mod;
}
}
swap(memo, prev);
}
return prev[m];
}
|
space complextiy: O( 26n + m )
實際上空間複雜度可以再優化,前面的 freq 可以不用先算。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
| int numWays(vector<string>& words, string target) {
int n = words[0].size();
int m = target.size();
int mod = 1e9 + 7;
vector<long long> memo(m + 1, 0), prev(m + 1, 0);
prev[0] = 1;
for (int i = 1; i <= n; i++){
vector<int> freq(26, 0);
for (string &word: words){
freq[word[i - 1] - 'a']++;
}
for (int j = 0; j <= i && j <= m; j++){
if (j == 0){
memo[j] = 1;
}
else {
memo[j] = (prev[j] + prev[j - 1] * freq[target[j - 1] - 'a']) % mod;
}
}
swap(memo, prev);
}
return prev[m];
}
|
space complextiy: O( n + m )